
第二正規化って何?データベースを勉強しているうちに、混乱してきた・・・。
という人向けの記事です。
第一正規化では、余分だったりはみ出ているデータを整理して。
すべてのデータが同じ形となるように整理しました。
第二正規化は、正規化の第二段階。
ダブってたり、回りくどい部分をなくすのが目的です。
わかりやすく言うと、「主キーにくっつく、データの繰り返しを整理すること」だと思ってください。
主キーがわからん!
となった人は、主キーについての説明も見てほしいのですがひとまず、「他とかぶることのない、データのメイン部分の繰り返しを整理する」と思ってください。
第二正規化とは、主キーにくっつく、データの繰り返しを整理
第二正規化とは、主キーにくっつく、データの繰り返しを整理することです。
正規化とは?
その前に、正規化について、まだイマイチ理解できていない人は、ここを読んでくれるとうれしいです。
※第一正規化の記事でも解説しているので、飛ばしてもらって大丈夫です。
正規化についてざっくりと言ってしまえば、「余分だったり、ダブってたり、回りくどい部分をなくすこと」です。
試験的には「冗長性(じょうちょうせい)をなくす」みたいに言ったりします!
なぜ正規化をする必要があるのか?
なんでダブってたらダメなの?
「データを直したいと思ったときに不便だし、つじつまが合わなくなるから」です。
例えば、ある企業が、”ABC”という商品を販売してて、途中で”ABD”に変わったとします。
データベースというデータを入れる箱のあちこちに、”ABC”という名前が使われていたら、すべて”ABD”に直さないといけません。
商品名が変わるたびに、あちこち修正するのは面倒です。
不便だし、修正モレが発生すれば、つじつまが合わなくなります。
なので、ABCという名前をデータベースで管理するなら、なるべくダブりが発生しないように管理する必要があります。
第二正規化・第三正規化の根本の考え方!
主キーとは?
それと、主キーって何?
主キーは、「他と、かぶることのないデータ」です。
例えば、社員番号とか、学生番号が身近でわかりやすいです。
社員が何人になろうが、学生が入学しようが、「番号」が他の人とかぶることは、あり得ません。

例えば、ある会社の社員番号で、「1000001」という番号があったとして。
「1000001」という番号は誰のことを言っているのか?
番号から、社員の名前が、わかるようになっています。
もし、「1000001」が、AくんとBさんの2人を指していて。
仲良く(?)番号を共有していて、AくんとBさんを区別できないとしたら。
「社員番号の意味ねぇじゃん」となりますよね(´▽`*)。
なので、主キーとなるデータは、他とかぶることは、絶対にありえません。
第二正規化は、主キーにくっつく、データの繰り返しを整理する
そして、第二正規化とは、他とかぶることのない、主キーにくっつく、データの繰り返しを整理します。
なんとなく、わかったような、わからないような。
実際に見てみないことには、よくわからんと思うので、これからやりかたを説明します。
少~し説明が長くなるので、ゆっくり読んでください!
第二正規化のやりかた
データのかたまりを登録するイメージ
例えば、
- 「社員番号」(主キーで絶対にかぶらない)
- 「社員名」(社員番号から必ずわかるもの)
- 「部署コード」
- 「部署名」(部署コードから必ずわかるもの)
- 「担当商品コード」(主キーで絶対にかぶらない)
- 「担当商品」(担当商品コードから必ずわかるもの)
の6つのデータのかたまりを保存するとします。
この場合は、社員番号と担当商品コードの2つの組み合わせが重複しなければ、OK。
これらを保存するための箱を、データベースに用意して、下のようにデータを保存していたとします。
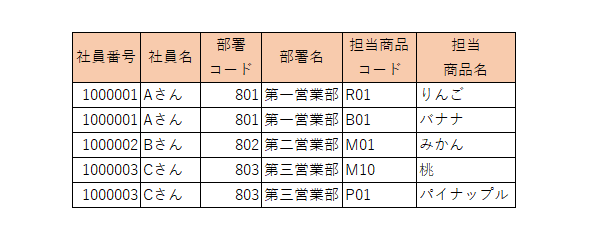
厳密に言えば、上の構造だと、社員番号と担当商品コードの2つが、主キーでないとおかしいのだけど、説明を簡単にするために、ひとまず社員番号だけを考えます。
実際に出題された場合は、社員番号と担当商品コードに対して、同じことをしないと正解にならないですが、今のうちは「ふ~ん」でいいです。
社員名が変わったときに変更するのが大変
たとえば、今データベースに登録している社員名を、「Aさんの苗字が変わったから、Sさんに変更したい!」とします。
社員名の「Aさん」の部分は、すべて「Sさん」に変えないといけないですよね。
今の例だと「Aさん」が2つしかないけど、もし100万件とか、めっちゃ多くのデータがあったら。
全部を「Aさん」から「Sさん」に変えるのは、大変だしミスります。
あるいは、
AさんだけでなくCさんも!
ここには出てないけど、Pさんも!
みたいに、「他の人も!」となれば、全員分をしらみつぶしに確認するのは、大変です。
しらみつぶしに変更するのは大変だから社員名は別の箱で管理
それじゃあ、どうするの?
社員名を管理する箱を作ってしまえばいい!
つまりは、こういうことです。
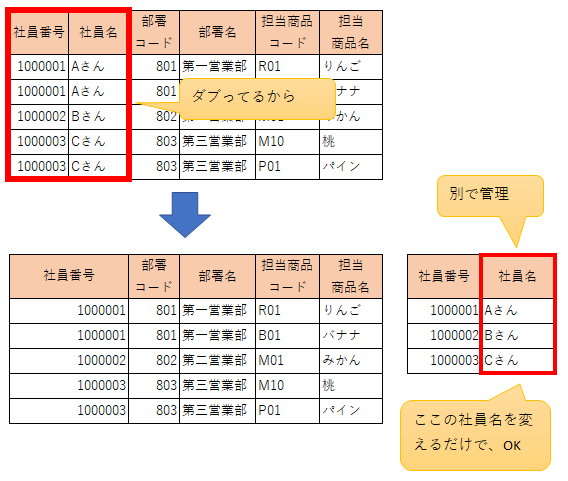
第二正規化をする前は、いちいち、
「1000001,Aさん|1000001,Aさん|1000002,Bさん|1000003,Cさん|1000003,Cさん」
みたいに。
主キーとなる「社員番号」と、主キーにくっつく「社員名」を毎回セットで書くから、くどいし面倒なわけです。
主キーに関連する一か所を変更すれば済むようにするのが第二正規化の基本
そこで社員名を、別で管理して1か所だけで管理したら、1か所を変更するだけで済みます。
かなりざっくりといえば、元のテーブルの社員番号から、別で管理している社員名を引っぱり出すだけで良いですからね(´▽`*)。
▼ざっくりイメージ
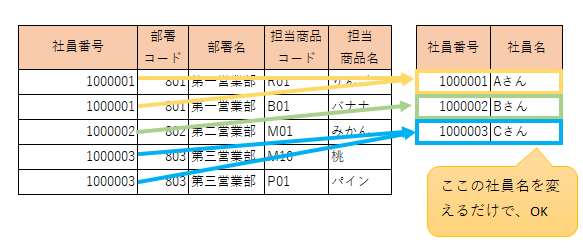
あくまでも、別で管理している社員名だけを変えればいいので、楽ちんです。
こんな感じで、第二正規化では、主キーにくっつく、データの繰り返しを整理していきます。
主キーにくっつくすべてのデータを別で管理してあげる。
これで、第二正規化の完成(担当商品コードも、この場合は第二正規化の対象)となります!
■最後はこんな形になる
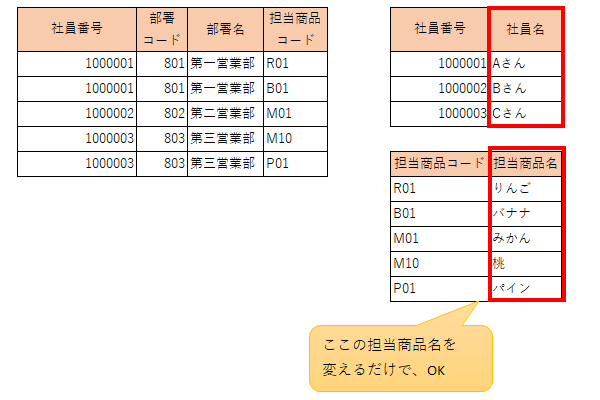
少しややこしい説明になりましたが、意味を理解しつつ演習を重ねながら覚えていってください!
第二正規化というからには、第一と第三の正規化がある
第二正規化というからには、第一と第三の正規化があります。
試験では、第二と第三が圧倒的に出る!
まとめ
第二正規化とは?主キーにくっつく、データの繰り返しを整理することです。
第二正規化をしっかりとやってあげないと、主キーにくっつくデータを更新したいな~となったときに、変える量がめちゃくちゃ多くなるかもしれないし。
更新で抜けているところがあるのもよくないし。
ということで、主キーにくっつくデータは別で管理してあげたほうがいいよね。というのが、第二正規化でした。
そして、第二正規化の次に、さらに第三正規化があるんだな~くらいに思ってくださいまし(-_-;)。
コメント